Le cadre Stade 2024 pour intégrer les LLM en psychothérapie — et sa formalisation en matrice par Garczynski
Elizabeth Stade et son équipe (Stanford, Penn, Johns Hopkins) proposent un cadre pour penser l'intégration des LLM en psychothérapie, articulé autour de trois niveaux d'autonomie (assistif, collaboratif, autonome). Luc Garczynski (UdeM, 2026) en formalise les applications en cinq axes et y ajoute deux catégories empiriques inédites.
Source analysée
Large language models could change the future of behavioral healthcare: a proposal for responsible development and evaluation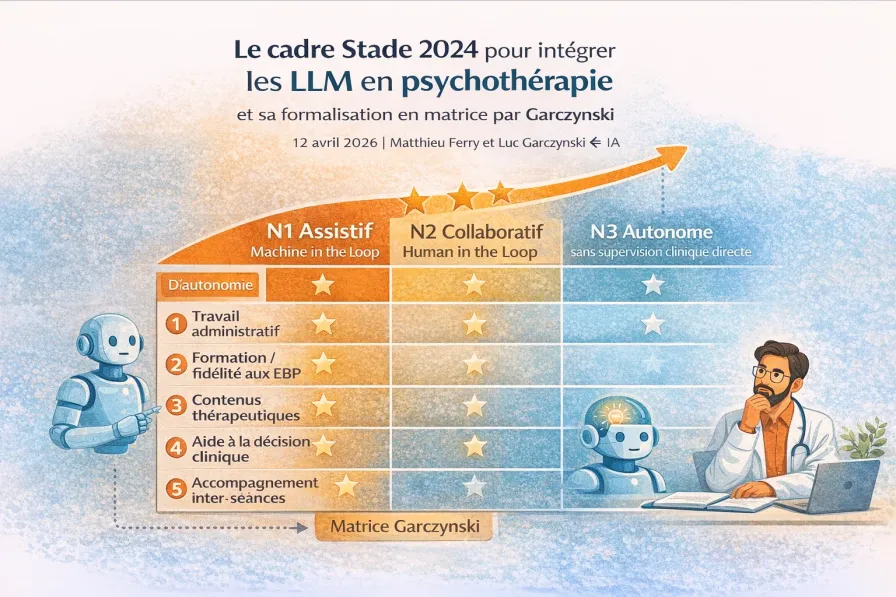
Pourquoi ce cadre, pourquoi maintenant
Depuis 2023, la discussion sur les LLM en psychothérapie tourne en rond entre deux pôles symétriques. D’un côté, les annonces enthousiastes : l’IA va démocratiser l’accès aux soins, augmenter la fidélité aux protocoles, libérer le clinicien de tâches chronophages. De l’autre, les alertes : les chatbots provoqueraient des passages à l’acte, fabriqueraient de la complaisance, dégraderaient l’alliance thérapeutique. Les deux camps citent des études — souvent les mêmes — pour conclure des choses opposées.
Ce blocage tient à un manque de vocabulaire commun. Tant qu’on parle de « l’IA en psychothérapie » comme d’un bloc indistinct, on ne peut ni évaluer rigoureusement, ni délibérer publiquement, ni légiférer prudemment. Avant de débattre, il faut distinguer : quel usage, à quel niveau d’autonomie, sous quelles conditions ?
C’est précisément ce que commence à faire le cadre proposé en avril 2024 par Elizabeth Stade et son équipe dans npj Mental Health Research. Il ne tranche pas le débat. Il outille la délibération en proposant un continuum d’autonomie à trois niveaux et en illustrant les domaines d’application clinique des LLM. Dans cet article, nous présentons d’abord ce cadre tel qu’il est publié, puis nous montrons comment Luc Garczynski l’a formalisé en matrice opérationnelle dans son travail empirique (UdeM, 2026) — une contribution originale qui clarifie, étend et révèle les limites du cadre théorique.
Structure de cet article
- Partie I — Le cadre Stade 2024 tel qu’il est publié : trois niveaux d’autonomie, applications, principes, forces et limites.
- Partie II — L’apport de Luc Garczynski : formalisation en cinq axes, matrice opérationnelle, découvertes empiriques.
- Partie III — Articulation avec les autres cadres d’évaluation (Hua, Choudhury, READI).
I. Le cadre Stade 2024
D’où ça vient
Le cadre est publié en avril 2024 sous le titre Large language models could change the future of behavioral healthcare: a proposal for responsible development and evaluation, dans npj Mental Health Research, revue partenaire de Nature. L’équipe est interdisciplinaire et institutionnellement lourde : Elizabeth Stade (Stanford HAI) en première auteure, Shannon Wiltsey Stirman (Stanford Psychiatry, science de l’implémentation TCC), Lyle Ungar (Penn, NLP), Robert DeRubeis (Penn Psychology, TCC), Johannes Eichstaedt (Stanford Psychology, World Well-Being Project), entre autres.
Le constat de départ est explicite, et il fait office de tonalité :
« Clinical psychology is an uncommonly high stakes application domain for AI systems. »
— Stade et al. (2024), npj Mental Health Research
Autrement dit : la psychothérapie n’est pas un domaine d’application comme un autre. Les erreurs y sont moins visibles que dans la radiologie, mais leurs conséquences peuvent être tout aussi graves — et beaucoup plus longues. Cette gravité n’autorise ni le rejet en bloc (qui prive d’usages potentiellement bénéfiques), ni l’enthousiasme générique (qui prive de garde-fous nécessaires). Elle exige une pédagogie de la distinction.
Les trois niveaux d’autonomie
C’est la contribution structurante explicite de Stade et al. L’analogie est assumée — celle des véhicules autonomes. De même qu’on ne déploie pas une voiture sans conducteur sans avoir d’abord testé l’aide au stationnement, on ne déploie pas un LLM en psychothérapie sans avoir d’abord validé son usage le plus encadré.
Assistif — Machine in the Loop
Le LLM exécute des tâches délimitées sous contrôle humain permanent. Chaque sortie est validée par le clinicien avant usage. Le clinicien reste le décideur unique ; le LLM augmente sa capacité sans jamais s’y substituer. C’est le niveau que les auteurs recommandent comme point d’entrée pour tout usage clinique, y compris pour des tâches administratives à faible risque.
Collaboratif — Human in the Loop
Le LLM participe à un raisonnement partagé avec le clinicien, qui conserve la décision finale. Le modèle suggère des options thérapeutiques, des formulations, des plans d’intervention ; le clinicien sélectionne, adapte et assume. Ce niveau implique une confiance accrue dans les sorties du modèle et soulève des enjeux spécifiques de traçabilité (qui est responsable d’une suggestion reprise ?) et d’alliance thérapeutique (comment le patient perçoit-il un plan co-construit avec un LLM ?).
Autonome — sans supervision clinique directe
Le LLM opère sans supervision clinique directe pour des tâches délimitées. C’est le niveau le plus risqué, réservé à des cas d’usage ayant fait l’objet d’une évaluation empirique rigoureuse et d’une validation réglementaire.
Les auteurs le présentent comme un horizon théorique conditionnel, non comme une recommandation immédiate. C’est précisément contre le déploiement prématuré à ce niveau que le cadre entier est construit.
La progression entre les niveaux n’est pas linéaire : les auteurs notent que certaines interventions plus structurées et protocolisées (TCC pour l’insomnie, exposition pour la phobie spécifique) pourraient atteindre le niveau collaboratif plus rapidement que des interventions flexibles ou personnalisées. Le stade 3 (pleinement autonome) reste un horizon dont la légitimité même fait débat — nous y revenons dans les limites.
Les applications cliniques telles que Stade les décrit
Le papier original ne propose pas de taxonomie numérotée. Les applications présentées sont organisées par type de tâche et par audience cible (clinicien, patient, stagiaire, superviseur, pair aidant). Voici les principales, regroupées fidèlement :
Travail administratif et documentation
Brouillons de notes d’évolution, résumés de séances, comptes rendus de dossier, aide à la facturation. C’est l’usage de moindre risque clinique et le plus immédiatement opérationnel. Cible : clinicien.
Mesure de la fidélité au traitement
Le LLM dérive automatiquement des scores d’adhérence et de compétence à partir de transcriptions de séances. Stade et al. notent que cette mesure est cruciale pour le développement et la dissémination des EBP, mais reste coûteuse et peu fiable par des moyens humains. Cible : chercheur, superviseur.
Feedback sur les devoirs thérapeutiques
Le LLM fournit un retour en temps réel sur les exercices TCC du patient (restructuration cognitive, registres de pensées). Cible : patient.
Formation et supervision de stagiaires
Le LLM identifie les forces et faiblesses des interventions du stagiaire à partir d’enregistrements de séances. Il peut aussi servir d’aide à l’empathie pour les pairs aidants (cf. travaux de Sharma et al.). Cible : stagiaire, pair aidant.
Accompagnement entre les séances
Soutien en temps réel hors rendez-vous : aide aux devoirs thérapeutiques, gestion de la détresse légère à modérée, psychoéducation personnalisée. C’est l’application la plus pertinente pour l’accès en zones sous-dotées, mais aussi celle qui exige les protocoles les plus stricts de détection du risque. Cible : patient.
Le papier fournit également une Table 2 (Imminent possibilities for clinical LLMs) qui croise des tâches concrètes avec des exemples d’entrée/sortie LLM. Ces applications illustrent un spectre de possibilités dont le niveau de risque varie selon le niveau d’autonomie choisi.
Deux exemples concrets
TherapyTrainer (Stade et al. 2025) — système expérimental utilisant un LLM pour noter automatiquement la fidélité d’un thérapeute à un protocole TCC à partir de transcriptions. Le LLM signale les écarts au manuel mais ne prend aucune décision sur la formation du thérapeute : c’est le superviseur humain qui interprète le signal et décide des suites. Archétype de l’usage assistif (N1).
Woebot — application grand public guidant l’utilisateur dans des exercices TCC entre les séances. Sur le papier, elle se positionne en N1 assistif. En pratique, sans clinicien dans la boucle en temps réel, la frontière avec le N3 autonome devient ténue. Le cadre Stade fournit ici les critères d’évaluation à appliquer : efficacité clinique mesurée, détection du risque suicidaire, équité d’accès, absence de renforcement de biais cognitifs. Ces critères restent inégalement satisfaits, et c’est précisément ce que le cadre permet de dire avec rigueur.
Principes directeurs (extraction éditoriale)
Le papier contient une section « Recommendations » qui énonce des principes transversaux dont nous avons extrait les cinq principes opérationnels suivants :
Le jugement clinique humain reste central à chaque niveau
Y compris en N3, le déploiement autonome n’évacue pas le jugement clinique : il le déplace en amont (conception du protocole, sélection des cas, surveillance) plutôt qu’en aval (validation séance par séance).
L’évaluation empirique est obligatoire avant toute progression de niveau
On ne passe pas d’un cas d’usage assistif à un usage collaboratif sans une démonstration empirique préalable de sécurité et d’efficacité au niveau précédent. Cette progression séquentielle est explicitement modelée sur les phases d’essais cliniques pharmacologiques.
L’engagement n’est pas un critère d’entraînement approprié
C’est une critique implicite mais frontale du RLHF tel qu’il est pratiqué dans les LLM grand public, et de la sycophantie qu’il fabrique.
Optimiser un LLM clinique sur l’engagement utilisateur, c’est reproduire les pathologies des réseaux sociaux dans le champ du soin.
Les populations vulnérables exigent des garde-fous spécifiques
Risque suicidaire, contenu délirant, troubles psychotiques : ces situations ne sont pas des cas particuliers à traiter après coup. Elles imposent des protocoles dédiés en amont du déploiement, à chaque niveau d’autonomie.
L’équité est un critère d’évaluation central, pas un correctif optionnel
Équité raciale, socioéconomique, linguistique et culturelle doivent être intégrées dès l’évaluation, pas ajoutées en surcouche. Un LLM qui fonctionne bien en moyenne sur une population WEIRD mais échoue sur des populations insuffisamment représentées dans les données d’entraînement ne satisfait pas le cadre.
Ce qui est solide dans le cadre
Un continuum d’autonomie immédiatement utilisable
Trois niveaux, une analogie mémorable (le véhicule autonome), un principe simple (monter en autonomie exige une preuve empirique) : un clinicien peut l’utiliser sans formation préalable pour situer un usage envisagé.
Une critique implicite mais centrale du RLHF
Le principe « l’engagement n’est pas un critère d’entraînement approprié » est, sous une forme courte, l’une des prises de position les plus fermes qu’on trouve dans la littérature sur les LLM cliniques. Stade et al. nomment ce que beaucoup d’articles techniques évitent : les LLM grand public sont entraînés à plaire, et plaire n’est pas soigner.
Une référence qui structure désormais les travaux empiriques récents
Depuis sa publication, le cadre Stade est devenu la grille de codage par défaut des études qualitatives qui interrogent les usages cliniques des LLM. Ce statut de référence n’est pas une garantie de qualité, mais c’est un fait à intégrer : lire un article publié après 2024 sans connaître le cadre Stade revient souvent à passer à côté de son architecture analytique.
Refus assumé du binarisme
Le cadre prend explicitement position contre les deux positions stériles (rejet technophobe / enthousiasme non critique). Cette posture n’est pas un compromis mou : elle est la condition d’une délibération technique informée.
Les limites du cadre original
Sous-théorisation de la relation thérapeutique
Le cadre traite l’alliance thérapeutique comme un critère d’évaluation parmi d’autres (à mesurer), plutôt que comme une condition de possibilité éthique. Les critiques fondées sur l’éthique du care (Malouin-Lachance et coll. 2025 sur la digital therapeutic alliance) soulignent que la relation n’est pas mesurable comme une variable indépendante : elle est constitutive du soin. Le cadre Stade crée le vocabulaire pour poser la question de l’alliance avec un dispositif ; il n’y répond pas.
La tension non résolue avec le déploiement populationnel
Face à la crise mondiale d’accès à la santé mentale, l’approche séquentielle et prudente du cadre Stade peut être perçue comme un luxe de pays à haut revenu avec des systèmes de santé fonctionnels. Rousmaniere et coll. (Lancet Psychiatry, 2025) défendent la thèse opposée : le déploiement populationnel est déjà en cours de facto, et la question n’est plus s’il faut déployer au niveau autonome mais comment rendre ce déploiement moins nocif. Le cadre Stade n’a pas de réponse à cette objection — il en est même le contre-modèle. C’est un constat que nous partageons : dans notre propre travail (Ferry & Malo, série en cours sur l’analyse des conversations patient-LLM), nous posons exactement cette question en termes concrets : comment forger les instruments théoriques et pratiques pour étudier ces usages, en encadrer les risques, et identifier les synergies possibles avec une psychothérapie humaine.
Une carte sans jalons
Le cadre dit que la progression d’un niveau d’autonomie au suivant exige une évaluation empirique — mais il ne précise pas quelle évaluation, sur quels critères, combien de temps, avec quel comparateur. C’est une feuille de route dont les jalons restent à écrire. C’est précisément ce vide opérationnel que READI (Stade et al. 2025), l’extension directe du cadre, commence à combler avec ses six critères d’évaluation pré-déploiement.
Généralisation culturelle limitée
Le cadre est produit dans un contexte américain (Stanford, Penn, VA Palo Alto) et ses exemples de déploiement présupposent des systèmes de santé, des pratiques cliniques et des populations anglophones. Son applicabilité directe au contexte québécois (OPQ, Loi 25), européen (RGPD, spécificités culturelles) ou francophone élargi (terminologie clinique, ressources validées) reste sous-théorisée. Il faudra l’adapter, pas seulement le traduire.
Des applications dispersées, pas une taxonomie
Le papier illustre un large spectre d’applications mais ne les organise pas en catégories systématiques. Le lecteur retient les trois niveaux d’autonomie — clairs et mémorables — mais reste avec une liste d’applications non hiérarchisée. C’est précisément cette limite que le travail de Garczynski vient combler.
II. L’apport de Luc Garczynski — du cadre théorique au terrain clinique
Première reprise empirique francophone
En 2026, Luc Garczynski (Université de Montréal, PSY6008) conduit la première étude qualitative francophone qui utilise le cadre Stade comme architecture analytique. Recherche Descriptive Interprétative (RDI, Thorne 2016) — entretiens semi-structurés avec quatre psychologues TCC en pratique privée au Québec. L’apport est triple.
La formalisation en cinq axes d’application
Le texte de Stade et al. présente des applications dispersées, organisées par type de tâche et par audience. Garczynski les consolide en cinq axes d’application pour structurer son canevas d’entretien et son codebook déductif. C’est une contribution analytique originale — pas une simple traduction du cadre.
Travail administratif et organisationnel
Documentation clinique, synthèse de séances, brouillons de notes d’évolution, soutien à la facturation, tenue de dossier conforme. C’est le domaine de moindre risque clinique direct, et empiriquement le plus adopté en pratique privée — les sorties passent par une relecture humaine avant versement au dossier.
Formation professionnelle et fidélité aux pratiques fondées sur les preuves
Le LLM sert de partenaire de simulation pour les thérapeutes en formation : jeux de rôle cliniques, mesure de la fidélité aux protocoles manualisés (TCC, DBT, exposition), retour immédiat sur la compétence. Cet axe adresse directement la crise de diffusion des EBP : les pratiques validées restent largement sous-utilisées faute de supervision accessible. TherapyTrainer (Stade et al. 2025) en est un exemple opérationnel.
Production de contenus pour le patient
Le LLM génère ou personnalise des supports thérapeutiques destinés au patient : exercices de restructuration cognitive, psychoéducation adaptée au niveau de littératie, fiches de suivi des humeurs, matériel de pleine conscience. La personnalisation est l’avantage distinctif ; elle exige un contrôle de sortie rigoureux pour éviter formulations problématiques et glissements théoriques.
Aide à la décision clinique
Conceptualisations de cas, hypothèses diagnostiques différentielles, ajustements de plans de traitement. C’est l’axe de plus haute complexité clinique : le jugement du clinicien reste décisionnaire, mais le LLM augmente la surface d’hypothèses explorées. Cet axe requiert le niveau d’autonomie le plus bas possible — jamais autonome. C’est aussi le terrain privilégié de la sycophantie clinique, où le LLM peut valider une hypothèse prématurée du clinicien plutôt que de proposer des alternatives divergentes.
Accompagnement entre les séances
Soutien en temps réel entre les rendez-vous : aide aux devoirs thérapeutiques TCC, gestion des situations de détresse légère à modérée, rappel des outils appris en séance. C’est l’axe le plus pertinent pour l’accès en zones sous-dotées, mais aussi celui qui exige les protocoles les plus stricts de détection du risque (idéation suicidaire, crise aiguë) et d’escalade vers l’humain.
La matrice axes × niveaux
Croiser les cinq axes de Garczynski avec les trois niveaux de Stade donne une matrice 5 × 3 dans laquelle chaque cellule correspond à un type d’usage dont l’évaluation et les garde-fous se discutent séparément. Tous les usages ne sont pas légitimes : certaines cellules (par exemple aide à la décision diagnostique en autonome) sont non-recommandées par défaut.
| Axe d’application (Garczynski) | N1 Assistif | N2 Collaboratif | N3 Autonome |
|---|---|---|---|
| A1 — Administratif | Recommandé | Possible | Non recommandé |
| A2 — Formation / EBP | Recommandé | Possible | À évaluer |
| A3 — Contenus patient | Recommandé | Possible avec validation | À évaluer |
| A4 — Décision clinique | Possible | Avec prudence | Non recommandé |
| A5 — Inter-séances | Possible | Avec prudence | Conditionné à essai clinique |
Les catégories inductives — ce que le terrain révèle
Au-delà du codage déductif issu de Stade, Garczynski identifie deux phénomènes émergents absents du cadre original. Ce sont, pour nous, les trouvailles les plus précieuses — celles qui désignent les limites du cadre théorique.
La réassurance émotionnelle — signature clinique de la sycophantie
Les cliniciens interrogés utilisent le LLM dans les moments de doute clinique pour valider que leur raisonnement est conforme aux modèles TCC. Le LLM, structurellement entraîné à produire des réponses plaisantes (sycophantie), confirme quasi systématiquement l’hypothèse du clinicien — ce qui réduit l’incertitude et la charge émotionnelle, mais peut aussi renforcer des biais de confirmation. Le cadre Stade critique bien l’optimisation sur l’engagement, mais ne thématise pas explicitement la sycophantie comme risque pour le clinicien lui-même. C’est Garczynski qui en fournit la première documentation empirique.
Le tabou professionnel — dimension sociologique absente
Les psychologues décrivent un malaise à discuter de leur usage des LLM avec leurs pairs et superviseurs, par crainte de plaintes à l’Ordre des psychologues du Québec (OPQ) et de jugement professionnel. Ce tabou n’est pas anecdotique : il bloque la construction collective de normes d’usage et produit un déploiement souterrain, non supervisé, non documenté. C’est une dimension sociologique du déploiement entièrement absente du cadre Stade — qui présuppose un environnement professionnel ouvert à la discussion et à la régulation collaborative.
Risque de circularité méthodologique : quand une taxonomie devient le cadre de codage des études empiriques qui la mobilisent, ces études tendent à confirmer la pertinence du cadre sans le tester indépendamment. Les catégories inductives qui émergent malgré le cadre (réassurance émotionnelle, tabou professionnel) sont alors les plus précieuses — ce sont elles qui désignent les angles morts, et donc les frontières du cadre.
Découvrir notre article présentant l’étude de Garczynski
III. Articulation avec d’autres cadres d’évaluation
Le cadre Stade n’est pas seul. Il s’articule de façon complémentaire avec d’autres frameworks que nous avons décryptés sur ce site :
Hua et coll. 2025 (T1/T2/T3) vous dit où se situe une étude dans le parcours de validation. Le cadre Stade vous dit quel usage cette étude évalue (et la matrice de Garczynski vous dit dans quelle cellule). Croisés, ces cadres permettent de répondre à la question : « Cette étude prouve-t-elle quelque chose pour le cas d’usage qui m’intéresse ? »
Choudhury 2022 sur la validité écologique vous dit pourquoi les résultats d’une étude T1 ne se traduisent pas mécaniquement en bénéfice clinique réel — et quels facteurs humains (confiance, charge cognitive, accountability) doivent être pris en compte. Le cadre Stade ne thématise pas ces facteurs ; Choudhury complète ce manque.
READI (Stade et al. 2025), extension opérationnelle directe du cadre 2024, ajoute six critères d’évaluation pré-déploiement : sécurité, confidentialité, équité, efficacité, engagement, implémentation. Là où le cadre 2024 pose le quoi (quel usage, à quel niveau d’autonomie), READI fournit le comment (sur quels critères auditer avant de déployer). C’est le complément le plus direct.
L’ensemble Hua + Choudhury + Stade + Garczynski + READI forme aujourd’hui le cœur méthodologique le plus complet pour penser l’évaluation des LLM en santé mentale. Aucun de ces cadres ne suffit seul. Ils se complètent.
Ce que ça change pour vous, cliniciens
Utilisez la matrice avant de discuter
Avant de débattre de « l’IA en thérapie », placez l’usage envisagé sur la matrice. Quel axe ? Quel niveau ? La discussion qui suit est immédiatement plus précise. C’est un protocole de désamorçage des polarisations stériles, et il fonctionne aussi bien dans une réunion d’équipe que dans un courrier à un ordre professionnel.
Ne confondez pas « structuré par Stade » et « validé par Stade »
Le cadre fournit une grille de codage ; il n’évalue pas. Une étude qui « applique le cadre Stade » ne devient pas plus solide pour autant. Posez toujours les questions classiques : quel niveau de preuve (T1/T2/T3 selon Hua), quel comparateur, quelle population, quelle durée, quels critères primaires.
Travaillez les angles morts plutôt que la matrice
La matrice est solide comme outil de cadrage ; l’enjeu de recherche est ailleurs. Sycophantie clinique, alliance digitale, déploiement populationnel pragmatique, adaptation aux contextes francophones : c’est sur ces marges que les contributions originales sont possibles. C’est la stratégie que nous adoptons dans notre collaboration avec Luc Garczynski.
Référence analysée : Stade, E. C., Stirman, S. W., Ungar, L. H., Boland, C. L., Schwartz, H. A., Yaden, D. B., Sedoc, J., DeRubeis, R. J., Willer, R., & Eichstaedt, J. C. (2024). Large language models could change the future of behavioral healthcare: a proposal for responsible development and evaluation. npj Mental Health Research, 3(1), 12. https://doi.org/10.1038/s44184-024-00056-z — Accès libre.
Lectures complémentaires :
- Stade, E. C. et al. (2025). Readiness Evaluation for Artificial Intelligence-Mental Health Deployment and Implementation (READI): A Review and Proposed Framework. Technology, Mind, and Behavior — extension opérationnelle avec six critères d’évaluation.
- Rousmaniere, T. et al. (2025). Large-scale implementation of AI-based psychotherapy. Lancet Psychiatry — position alternative défendant le déploiement populationnel.
- Sharma, M. et al. (2023). Towards Understanding Sycophancy in Language Models. ICLR 2024 — origine de la critique structurelle du RLHF.
- Malouin-Lachance, A. et al. (2025). Does the Digital Therapeutic Alliance Exist? Integrative Review. JMIR Mental Health — critique fondée sur l’éthique du care.
Sur ce site :
- READI : six critères pour décider si une IA de santé mentale est prête
- Fiche chercheur Luc Garczynski
Série : Cadres d’évaluation de l’IA en santé
- Hua : trois niveaux de preuve IA en santé mentale
- Choudhury : validité écologique des études LLM
- CHART : transparence des chatbots de santé
- CONSORT-AI : transparence des essais cliniques IA
- CONSORT/SPIRIT 2025 : Science Ouverte oui, IA non
- PROBAST+AI : qualité des modèles de prédiction IA
- Stade 2024 + Garczynski 2026 : trois niveaux, cinq axes, matrice (cet article)
Mots-clés