Pourquoi une IA qui « surpasse les médecins » en labo peut échouer en cabinet : le cadre de Choudhury
Une IA qui obtient 95 % de précision sur des cas standardisés peut échouer en pratique clinique. Un chercheur en facteurs humains de West Virginia University explique pourquoi — et propose un cadre à trois niveaux que tout clinicien devrait connaître avant de se fier à une étude sur l'IA en santé.
Source analysée
https://humanfactors.jmir.org/2022/2/e35421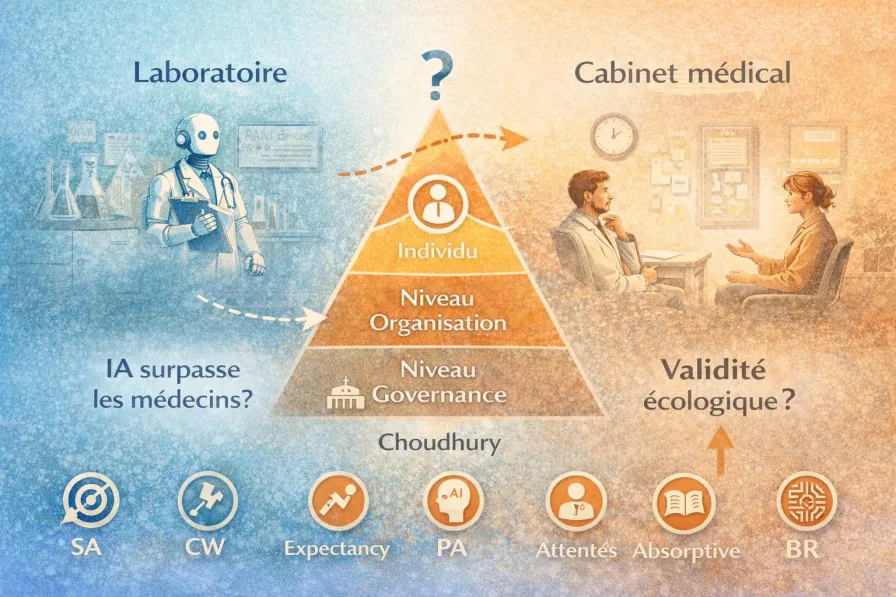
Le problème de départ
Vous avez peut-être lu ces titres dans la presse :
« ChatGPT surpasse les médecins en empathie et en qualité de réponse » — JAMA Internal Medicine, 2023
« L’IA atteint des performances de niveau expert aux examens médicaux » — Nature, 2024
« Les LLM sont des assistants médicaux fiables pour le grand public » — Nature Medicine, 2025
Ces études ont toutes un point commun. Elles évaluent l’IA dans des conditions qui n’ont rien à voir avec la pratique clinique réelle : des vignettes standardisées au lieu de vrais patients, des évaluateurs tiers au lieu de la relation soignant-soigné, des réponses textuelles isolées au lieu d’un suivi longitudinal.
C’est ce qu’on appelle le déficit de validité écologique : les résultats produits en conditions contrôlées ne prédisent pas le comportement du système dans l’environnement réel d’utilisation.
La question n’est pas « l’IA fonctionne-t-elle techniquement ? » mais « les cliniciens et les patients l’utiliseront-ils de manière sûre et efficace dans les conditions réelles de soin ? »
C’est exactement la question qu’aborde Avishek Choudhury, chercheur en facteurs humains à West Virginia University, dans un article publié dans JMIR Human Factors en 2022. Son cadre conceptuel explique pourquoi le fossé entre les performances en labo et l’adoption clinique existe — et quels facteurs humains le déterminent.
Le cadre en 5 minutes
L’idée centrale
Les modèles rationnels de décision clinique ne sont pas écologiquement valides. Ils présupposent :
Une information parfaite — le clinicien a accès à toutes les données pertinentes, dans un format clair
Une capacité cognitive idéale — le clinicien peut traiter toute l’information disponible sans fatigue ni surcharge
Une confiance optimale — le clinicien fait exactement le bon niveau de confiance à l’outil, ni trop ni trop peu
Des ressources illimitées — le clinicien a tout le temps, la formation et le soutien institutionnel nécessaires
Aucune de ces conditions n’est remplie en pratique clinique. Quand une étude teste l’IA dans ces conditions idéales, elle ne mesure pas la performance réelle — elle mesure la performance théorique maximale.
Les trois niveaux du cadre
Choudhury propose d’analyser l’adoption de l’IA clinique à travers trois niveaux imbriqués :
| Niveau | Question clé | Facteurs |
|---|---|---|
| Gouvernance | Quel cadre réglementaire et institutionnel encadre l’usage ? | Régulation, protocoles, accountability des parties prenantes |
| Organisation | L’institution est-elle prête à intégrer l’IA de manière responsable ? | Résilience systémique, accountability du clinicien, validité écologique du design |
| Individu | Le clinicien va-t-il utiliser l’IA de manière sûre et appropriée ? | Confiance, charge cognitive, conscience situationnelle, rationalité limitée |
Ce qui est remarquable dans ce cadre, c’est qu’il montre que l’adoption réelle de l’IA ne dépend pas seulement de la performance technique. Elle dépend de l’ensemble de l’écosystème dans lequel le clinicien opère.
Les six variables individuelles
Au niveau individuel — le plus détaillé du cadre — six variables déterminent si un clinicien utilisera ou non l’IA :
Situation Awareness (conscience situationnelle)
Le clinicien comprend-il ce que l’IA fait, pourquoi elle le fait, et dans quel contexte ? Sans cette compréhension, même une recommandation correcte peut être mal interprétée.
Cognitive Workload (charge cognitive)
Quand un clinicien est surchargé — 5 patients en attente, un appel urgent, un dossier complexe — il n’a pas la bande passante mentale pour interpréter correctement un output d’IA. C’est exactement le moment où il est le plus tenté de s’y fier aveuglément.
Expectancy (attentes)
Que s’attend-il à obtenir de l’outil ? Si ses attentes sont irréalistes (« l’IA va résoudre mon diagnostic ») ou défaitistes (« ce truc ne servira à rien »), l’usage sera dysfonctionnel.
Perceptions of AI (perception de l’IA)
L’attitude générale envers la technologie : enthousiasme, méfiance, indifférence. Ces perceptions préexistent à l’usage et le colorent fortement.
Absorptive Capacity (capacité d’absorption)
Le clinicien a-t-il les connaissances techniques minimales pour comprendre ce que l’IA lui dit ? Paradoxalement, plus les modèles sont complexes (deep learning, LLM), moins les cliniciens ont la capacité d’en évaluer les limites — c’est le problème de la boîte noire.
Bounded Rationality (rationalité limitée)
Concept de Herbert Simon (Nobel d’économie, 1978) : les êtres humains ne sont pas des machines à optimiser. Nous prenons des décisions « suffisamment bonnes » avec les ressources cognitives disponibles — pas des décisions optimales. L’IA ne supprime pas cette contrainte. Elle la déplace.
Ces six variables convergent vers deux médiateurs : la confiance dans l’IA et la perception du risque patient. Ce sont ces deux facteurs qui déterminent in fine si le clinicien utilisera ou non l’outil.
Ce que ça change pour la lecture des études
La grille de lecture du praticien
Quand vous lisez une étude affirmant que « l’IA surpasse les médecins », le cadre de Choudhury vous invite à poser six questions que l’étude n’aborde probablement pas :
| Variable ignorée | Question à se poser | Conséquence si absent |
|---|---|---|
| Charge cognitive | Les cliniciens de l’étude travaillaient-ils dans des conditions réelles (multitâche, pression temporelle) ? | La performance mesurée est irréaliste |
| Confiance | Les utilisateurs faisaient-ils confiance à l’IA, et cette confiance était-elle calibrée ? | Pas de prédiction sur l’usage réel |
| Accountability | Qui est responsable si l’IA se trompe ? Le clinicien le sait-il ? | Hésitation ou usage non contrôlé |
| Conscience situationnelle | Les utilisateurs comprenaient-ils ce que l’IA faisait ? | Mauvaise interprétation des résultats |
| Rationalité limitée | L’étude présuppose-t-elle un décideur rationnel et parfaitement informé ? | Les résultats ne s’appliquent qu’aux conditions idéales |
| Sécurité patient | L’étude mesure-t-elle les conséquences des erreurs, pas seulement la précision ? | Les risques restent invisibles |
Articulation avec le framework de Hua
Ce cadre se combine puissamment avec le framework à trois niveaux de Hua et al. (World Psychiatry, 2025), qui classe les études en trois niveaux de preuve :
Bench testing — l’IA fonctionne-t-elle techniquement ? (vignettes, benchmarks, évaluations d’experts)
Faisabilité — les utilisateurs acceptent-ils d’interagir avec le système ?
Efficacité clinique — le système améliore-t-il la santé des patients ?
Le constat frappant de Hua : sur 160 études (2020-2024), les LLM représentent 77 % des études T1 (bench testing) mais seulement 16 % des études T3 (efficacité clinique). Les technologies les plus médiatisées sont les moins validées cliniquement.
La complémentarité : le framework de Hua vous dit où se situe une étude dans le parcours de validation. Le cadre de Choudhury vous dit pourquoi le passage d’un niveau à l’autre n’a rien d’automatique — et quels facteurs humains et organisationnels l’empêchent.
Ce qui est solide dans cette proposition
Fondements théoriques robustes
Le cadre s’appuie sur des modèles validés depuis des décennies en ergonomie cognitive : le Technology Acceptance Model (Davis, 1989), le modèle de situation awareness (Endsley, 1995), le cadre SEIPS pour la sécurité patient (Carayon, 2006). Ce n’est pas une construction ad hoc — c’est une synthèse rigoureuse.
L’interaction est pensée comme bidirectionnelle
Contrairement à la plupart des cadres qui pensent « l’IA fait → le clinicien reçoit », Choudhury reconnaît que l’IA apprend des inputs du clinicien (reinforcement learning). La qualité de l’interaction détermine la performance future du système — un cercle qui peut être vertueux ou vicieux.
Il nomme ce que les cliniciens ressentent intuitivement
« Je ne fais pas confiance à cet outil », « Je ne comprends pas comment il fonctionne », « Je ne sais pas qui sera responsable si ça tourne mal ». Ce ne sont pas des résistances irrationnelles au progrès — ce sont des facteurs humains légitimes que le cadre de Choudhury identifie et systématise.
Il opérationnalise la validité écologique
Plutôt que de simplement dire « il faut tester en conditions réelles », le cadre identifie les variables spécifiques à mesurer. C’est la différence entre « il faudrait mieux évaluer » et « voici les 6 facteurs qui déterminent si vos résultats de labo prédisent l’usage réel ».
Les limites — et pourquoi elles comptent
Descriptif, pas prescriptif
Le cadre identifie les facteurs et leurs relations. Il ne dit pas comment les optimiser. C’est comme si un clinicien identifiait les facteurs de risque d’une dépression sans proposer de protocole de traitement. Le diagnostic est utile, mais il appelle un plan d’action.
Validation empirique limitée
Le cadre a été soutenu par une seule enquête (265 cliniciens américains). C’est un début, pas une preuve. La validation longitudinale et interculturelle reste à faire.
Analogie clinique : c’est comme proposer un modèle étiologique d’un trouble sur la base d’une seule étude transversale. Le modèle peut être juste, mais la prudence s’impose.
L’angle mort du patient
C’est la limite la plus significative pour notre champ. Le cadre se concentre sur l’interaction clinicien-IA. Il ne traite pas de l’interaction patient-IA — or c’est précisément le cas d’usage des chatbots thérapeutiques, des applications de suivi inter-séances, et de tous les outils où le patient interagit directement avec l’IA sans médiation d’un clinicien.
Pour la psychothérapie : les variables de Choudhury (confiance, charge cognitive, rationalité limitée) s’appliquent aussi au patient — mais avec des particularités liées à la vulnérabilité psychique, au transfert, à l’alliance thérapeutique. Une extension du cadre pour l’interaction directe patient-IA reste à construire.
Toutes les IA ne se valent pas
Le cadre traite « l’IA clinique » comme un bloc homogène. Or un système d’aide à la décision diagnostique, un chatbot thérapeutique et un outil de transcription de séances ne posent pas les mêmes défis d’adoption, de confiance ou d’accountability — comme nous l’expliquions dans notre article sur les distinctions entre IA, chatbot, LLM et application. Les facteurs humains varient considérablement selon le type d’outil.
Notre position
Le cadre de Choudhury est un outil de pensée précieux pour tout clinicien qui veut évaluer les études sur l’IA en santé avec discernement. Son apport principal : transformer une intuition vague (« ces études ne reflètent pas la réalité ») en une grille d’analyse structurée avec des variables identifiables.
Combiné avec le framework de Hua, il offre une lecture à deux niveaux : Hua vous dit quel type de preuve une étude apporte (benchmark, faisabilité, efficacité clinique), et Choudhury vous dit pourquoi la preuve d’un niveau ne se transfère pas automatiquement au suivant.
Pour la psychothérapie assistée par IA, nous retenons trois enseignements :
Ne vous laissez pas impressionner par les benchmarks
Un LLM qui « surpasse les médecins » sur des vignettes standardisées a franchi une étape technique. Il n’a pas démontré qu’il améliorera la santé de vos patients dans les conditions réelles de votre cabinet — avec sa charge cognitive, ses contraintes de temps, et ses responsabilités légales.
Vos « résistances » à l’IA sont peut-être de la lucidité
Si vous ne faites pas confiance à un outil IA, que vous ne comprenez pas comment il fonctionne, ou que vous ne savez pas qui sera responsable en cas d’erreur — ce ne sont pas des résistances irrationnelles au progrès. Ce sont des facteurs humains légitimes que la recherche identifie comme déterminants de l’adoption sûre.
Exigez des études en conditions réelles
Quand un éditeur, un assureur ou un administrateur vous présente un outil IA en citant des études, demandez : cette étude a-t-elle mesuré les résultats cliniques avec de vrais patients, dans des conditions de pratique réelles, sur une durée significative ? Si la réponse est non, l’outil n’est pas « prouvé » — il est « prometteur ». La différence compte.
Référence analysée : Choudhury, A. (2022). Toward an Ecologically Valid Conceptual Framework for the Use of Artificial Intelligence in Clinical Settings: Need for Systems Thinking, Accountability, Decision-making, Trust, and Patient Safety Considerations in Safeguarding the Technology and Clinicians. JMIR Human Factors, 9(2), e35421. https://doi.org/10.2196/35421
Lectures complémentaires :
- Hua, Y., Siddals, S., Torous, J. et al. (2025). Charting the evolution of artificial intelligence mental health chatbots from rule-based systems to large language models: a systematic review. World Psychiatry, 24(2). https://doi.org/10.1002/wps.21352
- Choudhury, A. & Asan, O. (2023). Impact of Accountability, Training, and Human Factors on the Use of Artificial Intelligence in Healthcare. Human Factors and Ergonomics Society Best Article Award 2024.
- Davis, F. D. (1989). Perceived usefulness, perceived ease of use, and user acceptance of information technology. MIS Quarterly, 13(3), 319-340.
- Endsley, M. R. (1995). Toward a theory of situation awareness in dynamic systems. Human Factors, 37(1), 32-64.
Série : Cadres d’évaluation de l’IA en santé
- Hua : trois niveaux de preuve IA en santé mentale
- Choudhury : validité écologique des études LLM (cet article)
- CHART : transparence des chatbots de santé
- CONSORT-AI : transparence des essais cliniques IA
- CONSORT/SPIRIT 2025 : Science Ouverte oui, IA non
- PROBAST+AI : qualité des modèles de prédiction IA
Mots-clés
Concepts abordés
Définitions et concepts clés abordés dans cet article.