Why an AI That 'Outperforms Doctors' in the Lab Can Fail in the Clinic: Choudhury's Framework
An AI that achieves 95% accuracy on standardized cases can fail in real clinical practice. A human factors researcher at West Virginia University explains why — and offers a three-level framework every clinician should know before trusting an AI health study.
Source analysée
https://humanfactors.jmir.org/2022/2/e35421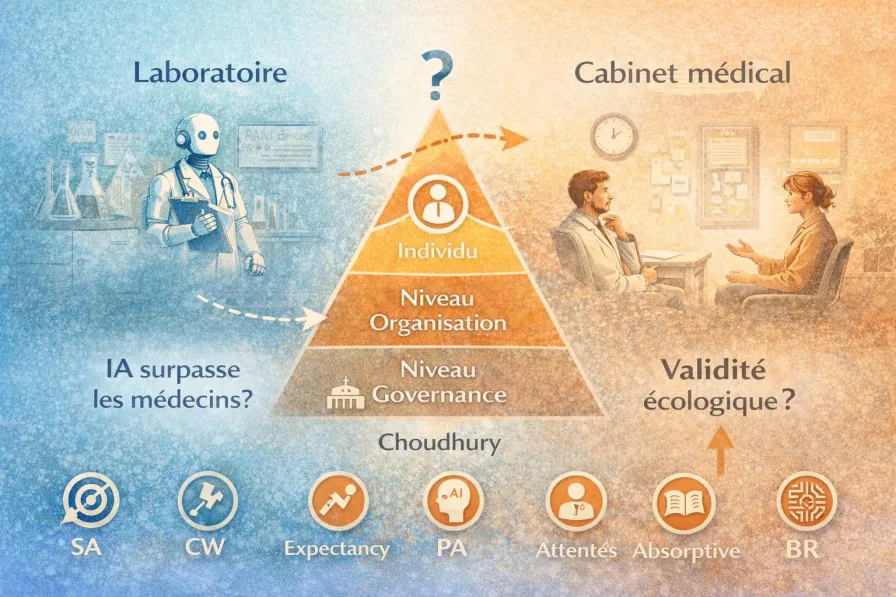
The Starting Problem
You may have seen headlines like these:
“ChatGPT outperforms physicians in empathy and response quality” — JAMA Internal Medicine, 2023
”AI achieves expert-level performance on medical exams” — Nature, 2024
”LLMs are reliable medical assistants for the general public” — Nature Medicine, 2025
These studies share a common thread. They all evaluate AI under conditions that bear no resemblance to real clinical practice: standardized vignettes instead of actual patients, third-party evaluators instead of the care relationship, isolated text responses instead of longitudinal follow-up.
This is what’s known as the ecological validity deficit: results produced under controlled conditions fail to predict how the system will behave in its actual environment of use.
The question is not “does the AI work technically?” but “will clinicians and patients use it safely and effectively under real-world conditions of care?”
This is precisely the question addressed by Avishek Choudhury, a human factors researcher at West Virginia University, in a paper published in JMIR Human Factors in 2022. His conceptual framework explains why the gap between lab performance and clinical adoption exists — and which human factors determine it.
The Framework in 5 Minutes
The Core Insight
Rational models of clinical decision-making are not ecologically valid. They assume:
Perfect information — the clinician has access to all relevant data, in a clear format
Ideal cognitive capacity — the clinician can process all available information without fatigue or overload
Optimal trust — the clinician trusts the tool at exactly the right level, neither too much nor too little
Unlimited resources — the clinician has all the time, training, and institutional support required
None of these conditions hold in clinical practice. When a study tests AI under these ideal conditions, it doesn’t measure real-world performance — it measures theoretical maximum performance.
The Three Levels
Choudhury proposes analyzing clinical AI adoption through three nested levels:
| Level | Key Question | Factors |
|---|---|---|
| Governance | What regulatory and institutional framework governs usage? | Regulation, protocols, stakeholder accountability |
| Organization | Is the institution prepared to integrate AI responsibly? | Systemic resilience, clinician accountability, ecological validity of design |
| Individual | Will the clinician use AI safely and appropriately? | Trust, cognitive workload, situation awareness, bounded rationality |
What makes this framework remarkable is that it shows AI adoption doesn’t depend on technical performance alone. It depends on the entire ecosystem in which the clinician operates.
The Six Individual Variables
At the individual level — the most detailed part of the framework — six variables determine whether a clinician will actually use the AI:
Situation Awareness
Does the clinician understand what the AI is doing, why it’s doing it, and in what context? Without this understanding, even a correct recommendation can be misinterpreted.
Cognitive Workload
When a clinician is overloaded — five patients waiting, an urgent call, a complex case file — they lack the mental bandwidth to correctly interpret AI output. That’s precisely when they’re most tempted to rely on it blindly.
Expectancy
What do they expect from the tool? If expectations are unrealistic (“the AI will solve my diagnosis”) or defeatist (“this thing is useless”), usage will be dysfunctional.
Perceptions of AI
Their general attitude toward the technology: enthusiasm, distrust, indifference. These perceptions predate actual usage and strongly color it.
Absorptive Capacity
Does the clinician have the minimum technical knowledge to understand what the AI is telling them? Paradoxically, the more complex the models (deep learning, LLMs), the less clinicians are equipped to assess their limitations — the classic black box problem.
Bounded Rationality
Herbert Simon’s concept (Nobel Prize in Economics, 1978): humans are not optimizing machines. We make “good enough” decisions with available cognitive resources — not optimal ones. AI doesn’t eliminate this constraint. It displaces it.
These six variables converge toward two mediators: trust in AI and perceived patient risk. These are the two factors that ultimately determine whether the clinician will use the tool.
What This Changes About Reading Studies
The Practitioner’s Reading Grid
When you read a study claiming “AI outperforms doctors,” Choudhury’s framework invites you to ask six questions the study probably doesn’t address:
| Overlooked Variable | Question to Ask | Consequence if Missing |
|---|---|---|
| Cognitive workload | Were the clinicians in the study working under real conditions (multitasking, time pressure)? | Measured performance is unrealistic |
| Trust | Did the users trust the AI, and was that trust calibrated? | No prediction of real-world usage |
| Accountability | Who is liable if the AI errs? Does the clinician know? | Hesitation or uncontrolled use |
| Situation awareness | Did the users understand what the AI was doing? | Misinterpretation of results |
| Bounded rationality | Does the study assume a rational, fully informed decision-maker? | Results only apply under ideal conditions |
| Patient safety | Does the study measure the consequences of errors, not just accuracy? | Risks remain invisible |
Connecting with Hua’s Framework
This framework combines powerfully with Hua et al.’s three-tier framework (World Psychiatry, 2025), which classifies studies into three evidence tiers:
Bench testing — does the AI work technically? (vignettes, benchmarks, expert evaluations)
Feasibility — do users accept interacting with the system?
Clinical effectiveness — does the system improve patient health outcomes?
Hua’s striking finding: across 160 studies (2020–2024), LLMs account for 77% of T1 studies (bench testing) but only 16% of T3 studies (clinical effectiveness). The most hyped technologies are the least clinically validated.
How they complement each other: Hua’s framework tells you where a study sits on the validation pathway. Choudhury’s framework tells you why moving from one level to the next is anything but automatic — and which human and organizational factors stand in the way.
What’s Solid in This Proposal
Robust theoretical foundations
The framework builds on models validated over decades in cognitive ergonomics: the Technology Acceptance Model (Davis, 1989), the situation awareness model (Endsley, 1995), the SEIPS framework for patient safety (Carayon, 2006). This is not an ad hoc construction — it’s a rigorous synthesis.
Interaction is conceived as bidirectional
Unlike most frameworks that assume “AI outputs → clinician receives,” Choudhury recognizes that AI learns from clinician inputs (reinforcement learning). The quality of the interaction determines the system’s future performance — a cycle that can be virtuous or vicious.
It names what clinicians feel intuitively
”I don’t trust this tool,” “I don’t understand how it works,” “I don’t know who’s responsible if it goes wrong.” These aren’t irrational resistance to progress — they’re legitimate human factors that Choudhury’s framework identifies and systematizes.
It operationalizes ecological validity
Rather than simply stating “we need real-world testing,” the framework identifies the specific variables to measure. That’s the difference between “we should evaluate better” and “here are the 6 factors that determine whether your lab results predict real-world usage.”
The Limitations — and Why They Matter
Descriptive, not prescriptive
The framework identifies factors and their relationships. It doesn’t tell you how to optimize them. It’s as if a clinician identified the risk factors for depression without proposing a treatment protocol. The diagnosis is useful, but it calls for an action plan.
Limited empirical validation
The framework has been supported by a single survey (265 U.S. clinicians). That’s a starting point, not proof. Longitudinal and cross-cultural validation remains to be done.
Clinical analogy: it’s like proposing an etiological model for a disorder on the basis of a single cross-sectional study. The model may be correct, but caution is warranted.
The patient blind spot
This is the most significant limitation for our field. The framework focuses on the clinician–AI interaction. It doesn’t address the patient–AI interaction — which is precisely the use case for therapeutic chatbots, between-session monitoring apps, and every tool where the patient interacts directly with AI without clinician mediation.
For psychotherapy: Choudhury’s variables (trust, cognitive load, bounded rationality) also apply to patients — but with particularities tied to psychological vulnerability, transference, and the therapeutic alliance. An extension of the framework for direct patient–AI interaction remains to be built.
Not all AIs are created equal
The framework treats “clinical AI” as a monolithic block. But a diagnostic decision-support system, a therapeutic chatbot, and a session transcription tool don’t pose the same adoption, trust, or accountability challenges — as we discussed in our article on the distinctions between AI, chatbot, LLM, and application. The human factors vary considerably depending on the type of tool.
Our Take
Choudhury’s framework is a valuable thinking tool for any clinician who wants to appraise AI health studies with discernment. Its main contribution: transforming a vague intuition (“these studies don’t reflect reality”) into a structured analytical grid with identifiable variables.
Combined with Hua’s framework, it offers a two-level reading: Hua tells you what type of evidence a study provides (benchmark, feasibility, clinical effectiveness), and Choudhury tells you why evidence from one level doesn’t automatically transfer to the next.
For AI-assisted psychotherapy, we retain three lessons:
Don’t be impressed by benchmarks
An LLM that “outperforms doctors” on standardized vignettes has cleared a technical hurdle. It hasn’t demonstrated that it will improve your patients’ health under the real-world conditions of your practice — with its cognitive load, time constraints, and legal responsibilities.
Your “resistance” to AI may be lucidity
If you don’t trust an AI tool, don’t understand how it works, or don’t know who bears responsibility when it errs — these aren’t irrational resistance to progress. They’re legitimate human factors that research identifies as determinants of safe adoption.
Demand real-world studies
When a vendor, insurer, or administrator pitches you an AI tool citing studies, ask: did this study measure clinical outcomes with real patients, under real-world practice conditions, over a meaningful duration? If the answer is no, the tool isn’t “proven” — it’s “promising.” The difference matters.
Reference analyzed: Choudhury, A. (2022). Toward an Ecologically Valid Conceptual Framework for the Use of Artificial Intelligence in Clinical Settings: Need for Systems Thinking, Accountability, Decision-making, Trust, and Patient Safety Considerations in Safeguarding the Technology and Clinicians. JMIR Human Factors, 9(2), e35421. https://doi.org/10.2196/35421
Further reading:
- Hua, Y., Siddals, S., Torous, J. et al. (2025). Charting the evolution of artificial intelligence mental health chatbots from rule-based systems to large language models: a systematic review. World Psychiatry, 24(2). https://doi.org/10.1002/wps.21352
- Choudhury, A. & Asan, O. (2023). Impact of Accountability, Training, and Human Factors on the Use of Artificial Intelligence in Healthcare. Human Factors and Ergonomics Society Best Article Award 2024.
- Davis, F. D. (1989). Perceived usefulness, perceived ease of use, and user acceptance of information technology. MIS Quarterly, 13(3), 319-340.
- Endsley, M. R. (1995). Toward a theory of situation awareness in dynamic systems. Human Factors, 37(1), 32-64.
Series: AI Evaluation Frameworks in Healthcare
- Hua: three tiers of evidence for AI in mental health
- Choudhury: ecological validity of LLM studies (this article)
- CHART: health chatbot transparency
- CONSORT-AI: transparency of AI clinical trials
- CONSORT/SPIRIT 2025: Open Science yes, AI no
- PROBAST+AI: quality of AI prediction models